AI导论
对AI的评价
- Software developers have the potential to be more productive than they have ever been in history
- With AI coding an engineer can pick up tech stacks and tools at an unprecedented pace
- You won’t be replaced by AI. You’ll be replaced by a competent engineer who knows how to use AI.
这三句话其实就是在表明,能够利用好AI的软件开发者将会是未来的主流,你需要的是学会如何最大化的利用AI工具,而不是被AI所替代。
LLMs are only as good as you are
- Good context leads to good code
- If you can’t understand your codebase, neither will an LLM
LLM和你的水平是相当的,你不理解你的代码,LLM也不会。它能够让你更快的提供你的上限,但AI能做到的上限和个人水平是密不可分的。
How LLMs Work
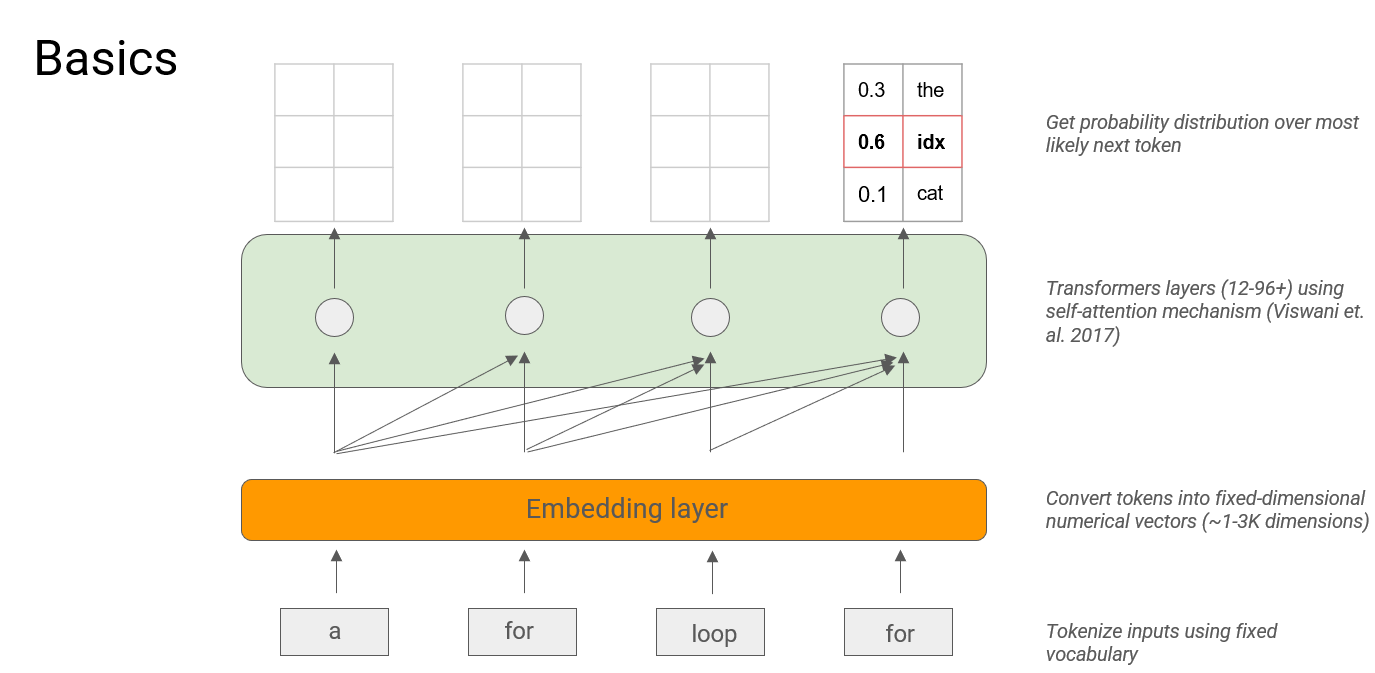
llm(大型语言模型)是用于下一个标记预测的自回归模型。
文本生成模型(比如GPT系列)一般分为三层:
- 输入层:将原始文本分割成更小的单元,也就是常说的token(词元)
- 嵌入层(embedding):将词元转换成固定维度的数值向量,让计算机可以捕捉词语的语义信息
- transformer层(使用自注意力机制的变换层):自注意力机制是一种用于帮助模型学习词语之间的句法和语义关系的内部数学机制,用于理解上文,预测下文。
- 输出层:获取最有可能的下一个token的概率分布。
Training Process
- 第一阶段:自监督预训练:在各种公共数据源(比如github代码库,stackExchange等)上进行训练,教会模型语言的基本概念。
- 第二阶段:监督微调:使用高质量,精心策划的提示-响应对,教会模型遵循指令。
- 第三阶段:偏好调优:收集同一提示的多个输出对,利用奖励模型,让模型输出和人类偏好(有用性,可读性,正确性)保持一致。
当前大模型发展的两大核心趋势:推理能力的进化和模型规模的扩张,推理模型的发展如下:
- 思维链训练:通过在训练数据中引入包含详细推理步骤的“思维链”,让模型学会分步骤、有逻辑地解决问题,而不是凭直觉给出答案。
- 工具使用集成:训练模型学会调用外部工具,如计算器、搜索引擎或代码解释器,以弥补其自身知识的局限,增强解决复杂任务的能力。
- 人类偏好对齐:收集人类对模型推理步骤的反馈,确保其思考过程不仅结果正确,而且逻辑清晰、符合人类的思维习惯。
- 强化学习评估:利用强化学习技术,让模型学会自我评估推理路径、识别错误并进行回溯修正,从而实现自我优化。
现在的GPT-3/CLaude 3.5 Sonnet参数量为1750亿,到GPT-4时已经高达1.8万亿。
In practive
LLM是一个强大的编程助手,但使用时必须考虑到其固有的局限性。
模型的优势在于:专家级代码补全,代码理解,代码修复。
局限在于
- 幻觉:模型可能生成不存在或者已经过时的API(解决方案:上下文工程)
- 上下文窗口限制:模型的上下文窗口可达10万-20万token,但不是所有token的处理效果都相同。(模型一般对开头和结尾的记忆更深刻,中间模型容易被以往)
- 延迟:处理请求根据任务复杂度导致的延迟实践(根据任务复杂度进行合理规划,最大化利用模型思考时间,但也会导致频繁的上下文切换)
- 成本:训练输出等需要大量成本
提示词工程 Prompting
对提示词的观点
- 提示词是与大语言模型沟通的通用语(lingua franca),也是一种有效的编程方式。
- 提示词正在从精确、刻板的“代码式”指令,进化为更自然、更口语化的“人类语言”。
- 提示词工程虽然有其难以捉摸的一面,但它并非纯粹的玄学,而是有一套可以学习和应用的方法论。由于LLM的黑盒本质,内部运行机制不完全透明,因此从输入到输出之间仅对用于而言带有一定的神秘感,但LLM也是经过多次实验验证的成熟技术,通过学习才能实现更好的应用。
提示词技术
Zero-shot prompting
零样本提示是一种最直接的提示方式,其核心是直接向大语言模型提出任务要求,而不提供任何支持信息或示例。它考验的是模型基于其预训练知识直接完成任务的能力。
K-shot prompting
K-shot prompting的本质是上下文学习(in-context learning)。与直接下达指令的零样本提示不同,这种方法会在提问时,额外提供几个“输入-输出”的示例,让模型通过模仿来学习任务的模式、格式或风格。
Chain-of-Thought Prompting, CoT
思维链提示通过要求模型一步步地展示其推理步骤,来解决那些需要多步逻辑才能完成的任务。这种方法能显著提高模型在复杂问题上的准确性和可解释性。
- 多样本思维链(Multi-shot CoT):
- 在提示中提供几个完整的“问题-推理过程-答案”的示例。
- 通过展示完整的推理轨迹(reasoning traces),让模型学习并模仿这种逐步思考的模式。
- 零样本思维链(Zero-shot CoT):
- 不提供具体示例,而是直接在问题后加上一句引导性的话,如“Let’s think step-by-step”(让我们一步步思考)。
- 通过简单的指令,激发模型内部的推理能力,使其自动分解问题并逐步解答。
Self-consistency Prompting
Self-Consistency Improves Chain of Thought Reasoning in Language Models自洽性提示的核心逻辑:不依赖单次生成的结果,而是通过生成多条推理路径并寻找它们的交集(最一致的答案),以此来显著提升模型解决复杂问题的准确率,并减少胡编乱造的情况。
- 多次采样和聚合:同一个问题让模型生成多个不同的回答,结合Cot技术,投票选择出现频率最高的结果作为答案
- 减少幻觉和错误:让模型探索多个推理路径,有利于识别过滤掉不合理的幻觉
Tool Use
工具使用是现代大型语言模型应用开发中的一个转折点。它标志着模型从单纯的“文本生成器”进化为能够与现实世界交互、解决实际问题并减少错误的“智能代理”。
- 允许模型向外部求助。比如当需要直到一个实时的时间天气,操作数据库,计算复杂数学题等问题时,模型可以通过利用外部工具得到准确结果。
- 减少幻觉和实现自主性关键技术:真实的外部工具提供真实数据,避免捏造事实。模型能够使用工具是通过AI agent的关键步骤,说明模型具备了自主行动能力。
Retrieval Augmented Generation, RAG
RAG 是让大模型变得“博学”且“靠谱”的关键技术。它通过外挂知识库的方式,解决了模型知识陈旧、缺乏私有数据以及容易产生幻觉的问题,并且是现代 AI 编程助手(如 Cursor)能够理解你整个项目代码库的核心原理。
- 注入上下文数据。通过将用户私有数据或特定领域的文档(上下文)注入到提示词中,让模型能够基于这些特定信息来回答,而不是仅依赖其训练数据。
- 保持模型更新。RAG 允许模型访问最新的信息(如今天的新闻或最新的代码库),而无需耗费巨资重新训练模型。
- 你能免费获得可解释性和引用。模型的答案是基于检索到的具体文档生成的,所以你可以追溯答案的来源(引用)。这增加了模型的可信度,让用户知道答案是从哪里来的(可解释性)。
- 减少幻觉。通过限制模型只能根据检索到的事实进行回答,可以显著减少模型“一本正经胡说八道”的情况。
Reflexion
核心思想是引导模型对自己的输出进行自我审视和修正(行动 - 观察 - 反思 - 调整)。过程如下
- 自我反思。这要求模型在完成一次任务后,不要直接结束,而是停下来,像一个编辑一样,重新审视自己刚刚生成的答案,评估其正确性和完整性。
- 环境反馈。模型在执行一个动作(如运行一段代码)后,会获得一个“环境反馈”(如编译错误信息或测试失败报告)。这个反馈会被作为新的上下文信息,添加到与模型的对话历史中,引导它进行下一轮的思考和修正。
- 多轮提示。这并非一次性的问答,而是一个“尝试-评估-修正”的循环。通过多轮交互,模型可以逐步逼近最优解
Meta Prompting
元提示是一种高级提示技术,侧重于任务和问题的结构和语法方面,而非具体内容细节。元提示的目标是构建一种更抽象、结构化的大型语言模型(LLM)交互方式,强调信息的形式和模式,而非传统的内容中心方法。
System Prompt
它是提供给大语言模型的第一条消息。这条消息通常是隐藏的,最终用户在与模型交互时是看不到的。它设定了模型行为的底层基调。
作用:设定人设,制定规则,定义风格。
一般LLM中的三个角色是:System Prompt,User Prompt,Assistant
Eg.
You are a helpful assistant that loves programming at the level of a senior software developer and is very detailed and pedantic in your answers.
基础定位:乐于助人;专业领域:热爱编程的资深技术人员;回答风格:详尽和精确
AI Prompt Engineering:A Deep Dive
这场圆桌讨论的核心问题其实只有一个:提示工程到底是什么,以及怎么把它做好。
讨论一开始,四位专家就给出了一个共识性的判断——提示工程不是写一段话,而是在设计一个系统。它包含清晰沟通、迭代测试、版本控制和边界管理,本质上是用自然语言承担代码的功能。“工程"这两个字落在哪里——不是落在一句完美的提示上,而是落在试错的范式上:你能随时重置、独立实验、反复调整,这是传统软件开发给不了的自由度。
然后深入到了提示工程师的能力模型。四位专家给出了三条不同的路径:Zach强调的是阅读——仔细读模型的输出,别猜它怎么理解指令,直接看它怎么执行的;Amanda强调的是让外行人来测试你的提示,她自己的精确度只有68%,远低于人类基准,这说明提示词里藏着大量隐式假设;而David强调的是极限挑战——别做那些写邮件式的简单任务,真正的成长来自尝试不可能的事情,比如让Claude打Pokemon。
那个Pokemon的案例是整段讨论里最直观的。David花了整个周末,叠加网格、构建ASCII地图、放大三千倍,最后发现模型在NPC连续性识别上根本过不去。他选择了放弃——不是因为能力问题,是他知道用四个月优化不如等下一代模型。这个判断本身就是提示工程的一个核心能力:知道什么时候该停。
之后进入了一个很重要的分水岭——预训练模型和RLHF模型的差异。 David指出一个关键现象:很多人把预训练时代的直觉错误地用到RLHF模型上——比如过度关注"这个内容在互联网上出现了多少次”,或者认为角色扮演是万能的。而Amanda的解释把这个问题讲透了:模型已经不是"一句话接一句话地模仿"的预训练模型了,它是一个经过RLHF微调、被训练成"帮助者"的系统。对模型说谎、让它扮演角色,本质上是没搞清楚对面是什么。两种方法论的分歧,根源在这里。
然后是那三段划分——企业级、研究型和通用对话提示词的差异。企业级提示词要被调用百万次,必须覆盖所有的边缘情况,提供明确的退路(比如"不确定就输出unsure");研究型提示词恰恰相反,只用一两个说明性示例,而且故意选和实际数据完全不同的例子(从事实文档提取信息,用儿童故事做示例),目的是不让模型被格式绑架;通用对话边界更宽松,人在循环中,错了随时改就好。整本书读下来,从定义到能力模型,从底层差异到场景分类,这个框架是完整的。
Assignment
作业个人提交仓库:Sutdown/cs146s
推荐资料